This is Part 1 in a series of practical guidelines that describe how to use Gephi for social network analysis (SNA) when using cuneiform sources. This blog post is helping you to acquire a dataset for SNA.
Part 1: Acquiring a Dataset via Prosobab
Part 2: Cleaning your Dataset
Part 3: Data Preparation for Gephi
Part 4: Data Import for a 2-mode Network
Part 5: Transforming a 2-mode Network into a 1-mode Network
See also the theoretical guide that describes how Assyriologists can apply SNA to cuneiform sources — Social Network Analysis and Cuneiform Archives.
Introduction
Network analysis has been used to study social media networks, business relationships, spread of information, literary style and language, and even disease transmission. The sources used for such studies can be letters, memberships of organizations, employment records, publication history, lists of words used by authors, linguistic markers, hospital records etc. The underlying principle of social network analysis is simple — individuals can be connected to each other by their co-occurrences with other individuals. In this series of blog posts, the social networks of individuals will be created by their co-occurrences in legal contracts.
Gephi has become one of the most used software for SNA in historical studies. It works on all operating systems, is free for download, and easy to use once you know the basics. In addition, it has a lot of help material on the Gephi website and on Github. It might, however, take a long time of reading about both Gephi and SNA, and many hours spent on tryouts, before the desired results show. To make this process easier, I have written down some essentials from acquiring a dataset to transforming a 2-mode network into a 1-mode network.
Dataset options
First of all, you need a dataset. Generally speaking, you can either use this dataset for exploration, or to answer specific research questions. In any case, you need to know your dataset quite well to explain certain patterns and clustering you will see on the graph. Therefore, working with network analysis requires going back and forth between the sources and the graphs. You might also need to restate your assumptions or research questions based on the results you get from studying your network. Not all questions can be answered by SNA equally eloquently, but in the meantime, you will learn things about your sources that are hard to catch by going through each document and taking notes based on memory.
Your dataset options to follow the instructions in this blog series are the following:
a) You are welcome to use your own dataset, i.e. information you have gathered on your own. If this dataset does not need any cleaning up, you can continue with Part 3 of the guidelines.
b) You can also download the dataset I have prepared (BR & MR dataset 2-mode). This dataset contains two contemporary, well published archives from Sippar: The Bēl-rēmanni//Šangû-Šamaš A archive from 570–485 BCE (Jursa 1999) and the Marduk-rēmanni//Ṣāhit-ginê A archive from 548–484 BCE (Waerzeggers 2014). The data in this file is exported from Prosobab, but it is already cleaned up and ready to be imported into Gephi. If you decide to use this dataset, you can continue with Part 4 of the guidelines.
c) Another option is to get your data from Prosobab (see below). This requires you to follow the cleaning up procedures described in Part 2.
Prosobab dataset
In order to acquire a dataset from Prosobab, click here to go to the search screen of the project website. Choose, for example, an archive or two from the same city, or texts written in one location. The screen in the middle loads all the entries in a certain field once you click on this field. You should use this screen to select an entry you are looking for, otherwise the search might not function properly. Remember to click “on” the boxes with the information you want to display in the search results, and click “off” the boxes with the information you do not want. You can also delete data later in Microsoft Excel or in Gephi, but adding new data columns can be complicated.
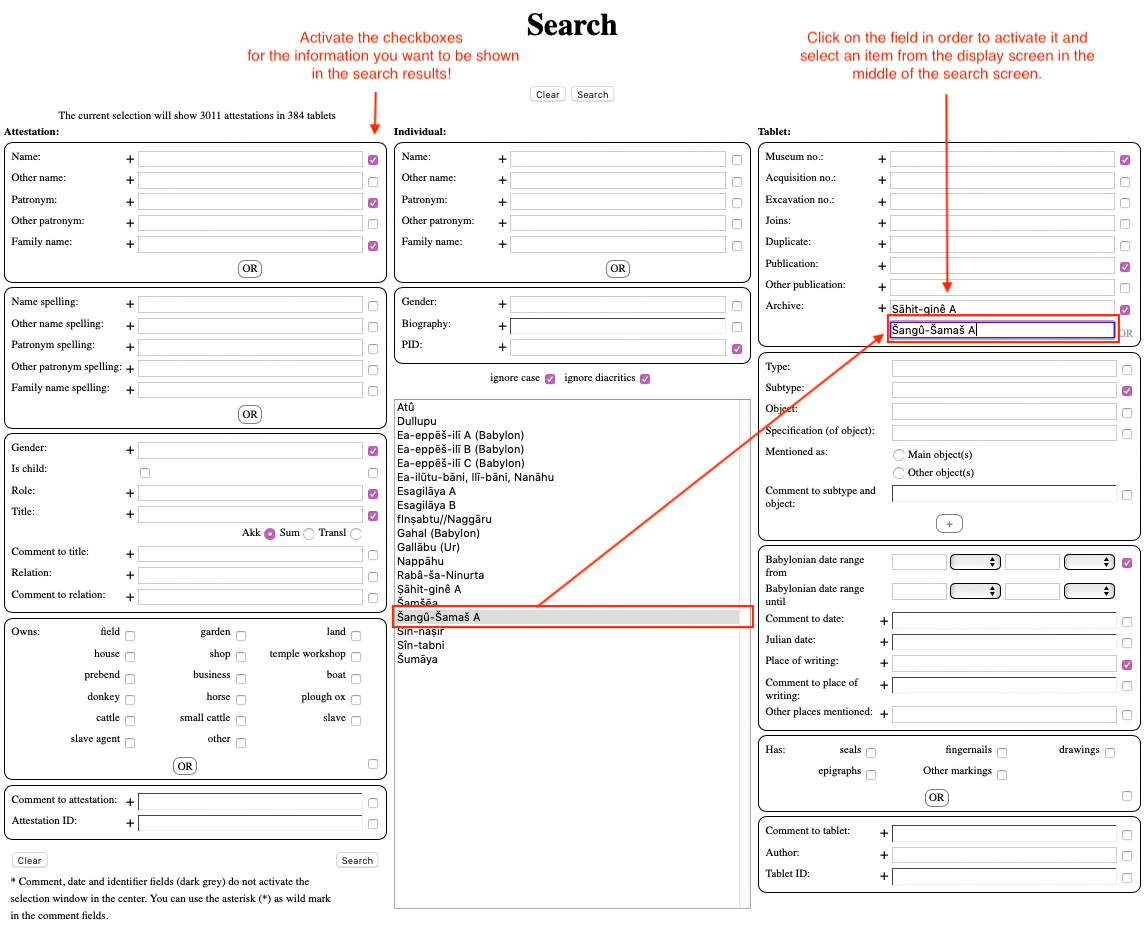
The most important information for SNA is something to identify the text with (e.g. museum number or publication information) and something to identify the individuals with (e.g. a unique name or a PID number in Prosobab). Make sure you have narrowed down the search results to a meaningful dataset as recommended in the section above. The smaller the dataset, the easier to prepare your data and learn from it. If you are not familiar with Prosobab and need more help to understand how the database works, see the guidelines on the Prosobab website.
| Tips for getting your data from Prosobab: |
| 1. From the Attestation column, click on Name, Patronym and Family name, and additionally information such as Gender, Role, and Title. |
| 2. From the Individual column, click on PID – that is a code for each individual and makes your work much easier because you no longer have to merge the name Attestations from the tablets into Individuals. |
| 3. From the Tablet column, click on Museum number, and additionally Publication, Archive, Subtype, Babylonian date range and Place of writing – this information will be useful to study the texts later on, without going back to check information about the documents in Prosobab. |
| 4. Do not forget to click off the rest of the boxes if they are selected! You can delete additional data columns later in your own file, but requiring more information could make the export of the data slower. |
| 5. Click on the button “search”. |
When you get to the search results screen in Prosobab, you can download the data in many formats using the button on the right corner above the search results. It is probably the easiest to export the data in MS-Excel format, as this is a well-known format to work with and you can import the data into Gephi using Excel. Besides, Excel allows you to save your data in other formats as well, such as a .csv-file or an .htm-file.
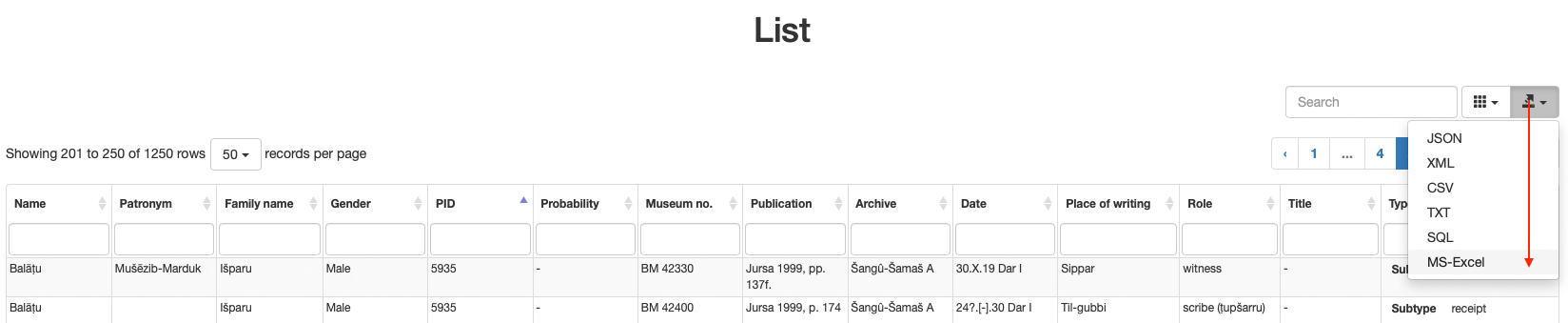
Opening the export file downloaded from Prosobab
When you export Prosobab search results in MS-Excel format and try to open the file, you might get a warning that says:
“The file format and extension of ‘Report.xls’ don’t match. The file could be corrupted or unsafe. Unless you trust its source, don’t open it. Do you want to open it anyway?”
You can safely click on “yes” and the file will open! Once the file is open, you should choose File > Save As…> from there you can rename your file and save it in .xls format. By doing that, you will not get notifications about the file type every time you open, save or close the worksheet. The file you downloaded contains a lot of data and not all of it is necessary for creating a simple network visualization. However, it is better to include more data in your “original file”, and then duplicate this file to a “working file” that you can safely edit, knowing that the information in its original form is easy to access.
If you use somebody else’s dataset (e.g. Prosobab), do not forget to refer to this!
The next blog post, Part 2, will describe the procedures necessary for the initial cleaning up of the data exported from Prosobab.
Bibliography
- Jursa, M. 1999: Das Archiv des Bēl-rēmanni (PIHANS 86), Istanbul and Leiden.
- Waerzeggers, C. 2014: Marduk-rēmanni: Local Networks and Imperial Politics in Achaemenid Babylonia (OLA 233), Leuven.
If you encounter any problems or find information that needs to be updated, you can let me know via email: m.seire[at]hum.leidenuniv.nl.
Author: Maarja Seire
Published on 28 January 2020